
Paper to HTML Tutorial
Last updated: August 10, 2022
Paper to HTML is a web app that converts scientific papers into HTML. It was designed primarily to help improve the accessibility of scientific papers to blind and low vision users and users of assistive reading technology like screen readers or text-to-speech, though it may also benefit users of mobile or small screen devices. This tutorial describes the main features of this site.
-
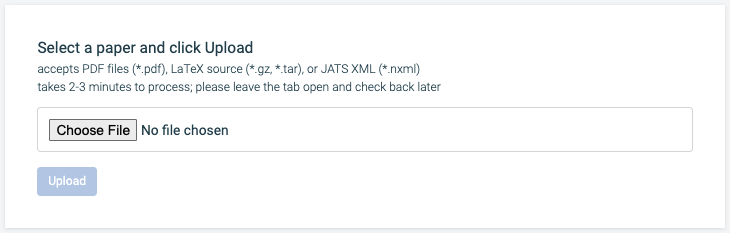
Upload a paper to Paper to HTMLSelect the "Choose File" button, and select a paper to process. This file is most often a PDF, but can also be the LaTeX source or XML document representing the paper. Once you have selected a paper, you can click the "Upload" button to begin processing. This usually takes between 30 seconds to 2 minutes for each new paper uploaded into the system. During this time, the system is running a series of machine learning models to extract content from the document.
-
When processing finishes, the resulting HTML is shownThis page can be bookmarked to return to this paper. The bookmark should default to saving based on the title of the uploaded paper, if it is properly extracted.

-
If major issues occur when processing the paper, these errors will be listed at the top of the page; these errors may indicate a low quality extraction

-
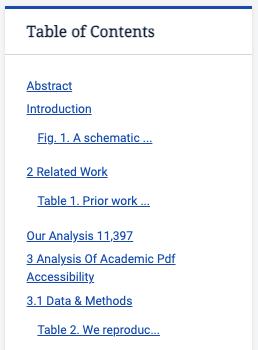
Navigate between sections of the paper using the extracted section headersThese are surrounded by the <h2> HTML tag, for example: the Data & Methods section
-
Navigate to extracted tables and figuresThese are surrounded by the <figure> HTML tag, for example: Figure 1
-
Section headings and extracted tables and figures are listed under the Table of Contents, which is located near the top of the page following the title and authors
-
Individual sections within the paper can be sharedFor example, this link goes to the Data & Methods section of the research paper about this app.
-
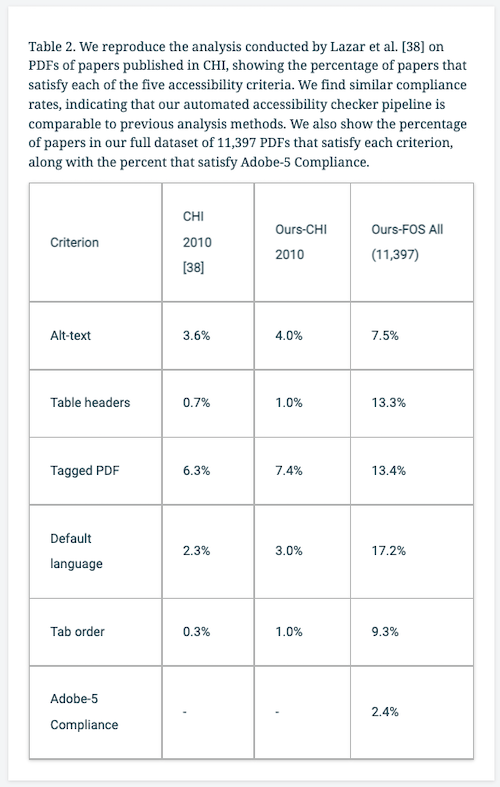
Some tables are converted into HTML for improved ease of readingFor example: Table 2 from an example paper
-
Bibliography entries are presented in the last section of the document, under the heading "References," as below:
-
Inline citations in the document are linked to their corresponding entries in the bibliography; return links in the bibliography after each reference entry can take the reader back to their previous reading location
![A snippet from the main text of a paper reads 'Scientific literature is most commonly available in the form of PDFs, which pose challenges for accessibility [6, 34].' When the '34' link is clicked, it takes the reader to the corresponding entry in the bibliography section, a paper by Nielsen and Kaley. The return to section links include a link to the Introduction section, which takes the reader back to the initial location of the link that reads '34'.](/static/tutorial/t10.png)
-
Low quality extractions are labeledYou may encounter the following text: "Not extracted; please refer to original document." These cases represent low quality extractions where the user may be better off going to the source document.


-
System shortcuts like Ctrl-F (find) and Ctrl-C (copy) work well with text in the HTML render

-
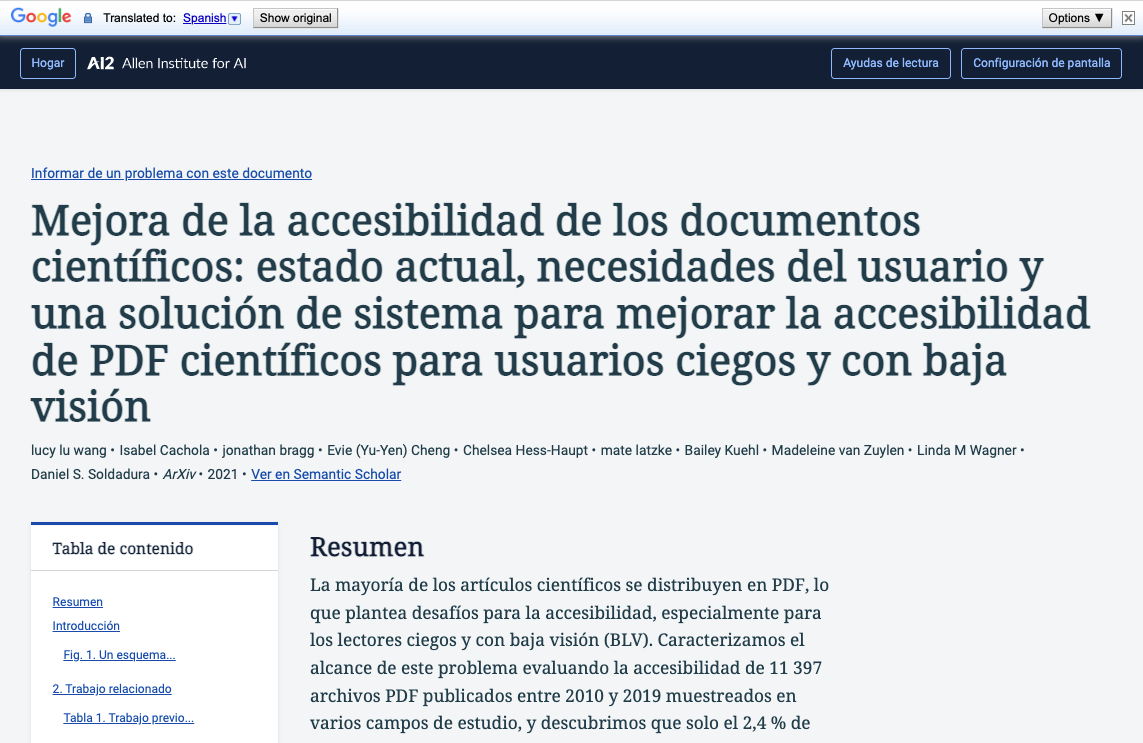
Paper to HTML can be used in conjunction with various web translation toolsFor example, Google Translate (available for Chrome and Firefox) can quickly translate the whole document into 133 languages. Of course, these are external tools so we have not performed any validation nor can we guarantee quality.
-
You can also save the HTML document for offline readingSelect 'Edit, Save as...' in your browser. However, please note that the within-document navigation links will not function in the saved page.
Still have unanswered questions? Check out our about page or email accessibility@semanticscholar.org.